Technology and Big Data have bridged much of the divide between corporations and their stakeholders. Political vacuums are foisting CEOs and brands into leadership roles all around the world. Our report offers corporate leaders a detailed peek ahead, with specific stake holder engagement strategies to meet the risks + opportunities of corporate stewardship head-on through 2020 and beyond.
Stakeholder Engagement – Local conflicts gaining global platforms
Hyper-transparency means that community disputes can be amplified to win worldwide prominence. “Local conflicts serve as mirrors for global trends. The ways they ignite, unfold, persist, and are resolved reflect shifts in great powers’ relations, the intensity of their competition, and the breadth of regional actors’ ambitions. They highlight issues with which the international system is obsessed and those toward which it is indifferent.” – Robert Malley at Crisis Group.
Stakeholder Engagement – Political and social risk converging
Political risk assessment is very important for any foreign organization that wants to make investments internationally. Political risks are the problems that can be faced by foreign investors due to the changes that can happen in the host country’s government policies, rules, laws and regulations. Check out Forbes post on Global Risk Outlook: Whither Political Risk In 2020 here.
Stakeholder Engagement – Business and human rights
The growing reach and impact of business enterprises have given rise to a debate about the roles and responsibilities of such actors with regard to human rights, and have led to the placement of business and human rights on the UN agenda. Neither legal compliance nor standard risk management tools are sufficient for companies who wish to survive and thrive in the new era. Rather, resilient companies will focus on core values, leadership and a more inclusive approach to business. Check out The UN Guiding Principles and how it applies to you and your buisness.
How can Estio Training help with your Business Analysis
To learn more about how Estio can support your business with developing Business Analysis skills, please take a look at our Business Analysis apprenticeship. To read more industry insights please take a closer look at our articles relating to the Business Analysis industry.
Top 10 Programming Languages In 2020 | Best Programming Languages To Learn In 2020 | Edureka
To find out more about the top programming languages this year, Please watch the video below. This video will introduce you to the most trending programming languages which you must learn to succeed in 2020. These programming languages are predicted to create a market shift and open up a huge number of job opportunities in 2020.
Get in touch!
To find out more about how Estio Training can support you with developing the very best Digital Apprentices, complete this form to arrange contact with one of our representitives.
What is Data Science? This is a question that a lot of people ask because we also have a field known as business Intelligence, but what are the differences? are they even known as the same things? In this post originally by Hemant Sharma of Edureka, we’ll be be covering the following topics.
The need for Data Science.
What is Data Science?
How is it different from Business Intelligence (BI) and Data Analysis?
The lifecycle of Data Science with the help of a use case.
By the end of this blog, you will be able to understand what is Data Science and its role in extracting meaningful insights from the complex and large sets of data all around us.
Let’s Understand Why We Need Data Science
Traditionally, the data that we had was mostly structured and small in size, which could be analyzed by using the simple BI tools. Unlike data in the traditional systems which was mostly structured, today most of the data is unstructured or semi-structured. Let’s have a look at the data trends in the image given below which shows that by 2020, more than 80 % of the data will be unstructured.
This data is generated from different sources like financial logs, text files, multimedia forms, sensors, and instruments. Simple BI tools are not capable of processing this huge volume and variety of data. This is why we need more complex and advanced analytical tools and algorithms for processing, analyzing and drawing meaningful insights out of it.
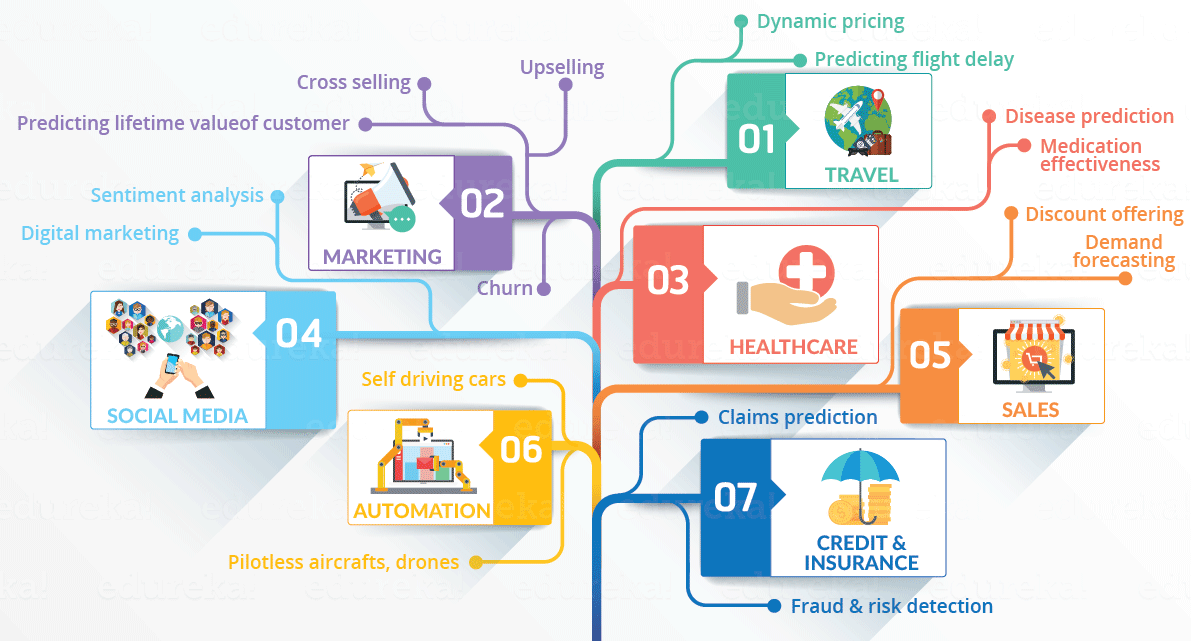
This is not the only reason why Data Science has become so popular. Let’s dig deeper and see how Data Science is being used in various domains.
How about if you could understand the precise requirements of your customers from the existing data like the customer’s past browsing history, purchase history, age, and income. No doubt you had all this data earlier too, but now with the vast amount and variety of data, you can train models more effectively and recommend the product to your customers with more precision. Wouldn’t it be amazing as it will bring more business to your organization?
Let’s take a different scenario to understand the role of Data Science in decision making. How about if your car had the intelligence to drive you home? The self-driving cars collect live data from sensors, including radars, cameras, and lasers to create a map of its surroundings. Based on this data, it takes decisions like when to speed up, when to speed down, when to overtake, where to take a turn – making use of advanced machine learning algorithms.
Let’s see how Data Science can be used in predictive analytics. Let’s take weather forecasting as an example. Data from ships, aircraft, radars, satellites can be collected and analyzed to build models. These models will not only forecast the weather but also help in predicting the occurrence of any natural calamities. It will help you to take appropriate measures beforehand and save many precious lives.
Let’s have a look at the below infographic to see all the domains where Data Science is creating its impression.
Now that you have understood the need for Data Science, let’s understand what is Data Science.
What is Data Science?
The use of the term Data Science is increasingly common, but what does it exactly mean? What skills do you need to become a Data Scientist? What is the difference between BI and Data Science? How are decisions and predictions made in Data Science? These are some of the questions that will be answered further.
First, let’s see what is Data Science. Data Science is a blend of various tools, algorithms, and machine learning principles with the goal to discover hidden patterns from the raw data. How is this different from what statisticians have been doing for years?
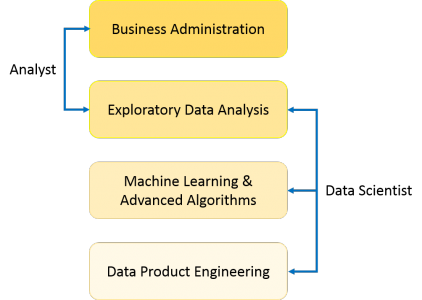
The answer lies in the difference between explaining and predicting.
As you can see from the above image, a Data Analyst usually explains what is going on by processing history of the data. On the other hand, Data Scientist not only does the exploratory analysis to discover insights from it, but also uses various advanced machine learning algorithms to identify the occurrence of a particular event in the future. A Data Scientist will look at the data from many angles, sometimes angles not known earlier.
So, Data Science is primarily used to make decisions and predictions making use of predictive causal analytics, prescriptive analytics (predictive plus decision science) and machine learning.
Predictive causal analytics – If you want a model that can predict the possibilities of a particular event in the future, you need to apply predictive causal analytics. Say, if you are providing money on credit, then the probability of customers making future credit payments on time is a matter of concern for you. Here, you can build a model that can perform predictive analytics on the payment history of the customer to predict if the future payments will be on time or not.
Prescriptive analytics: If you want a model that has the intelligence of taking its own decisions and the ability to modify it with dynamic parameters, you certainly need prescriptive analytics for it. This relatively new field is all about providing advice. In other terms, it not only predicts but suggests a range of prescribed actions and associated outcomes. The best example for this is Google’s self-driving car which I had discussed earlier too. The data gathered by vehicles can be used to train self-driving cars. You can run algorithms on this data to bring intelligence to it. This will enable your car to make decisions like when to turn, which path to take when to slow down or speed up.
Machine learning for making predictions — If you have transactional data of a finance company and need to build a model to determine the future trend, then machine learning algorithms are the best bet. This falls under the paradigm of supervised learning. It is called supervised because you already have the data based on which you can train your machines. For example, a fraud detection model can be trained using a historical record of fraudulent purchases.
Machine learning for pattern discovery — If you don’t have the parameters based on which you can make predictions, then you need to find out the hidden patterns within the data-set to be able to make meaningful predictions. This is nothing but the unsupervised model as you don’t have any predefined labels for grouping. The most common algorithm used for pattern discovery is Clustering. Let’s say you are working in a telephone company and you need to establish a network by putting towers in a region. Then, you can use the clustering technique to find those tower locations which will ensure that all the users receive optimum signal strength.
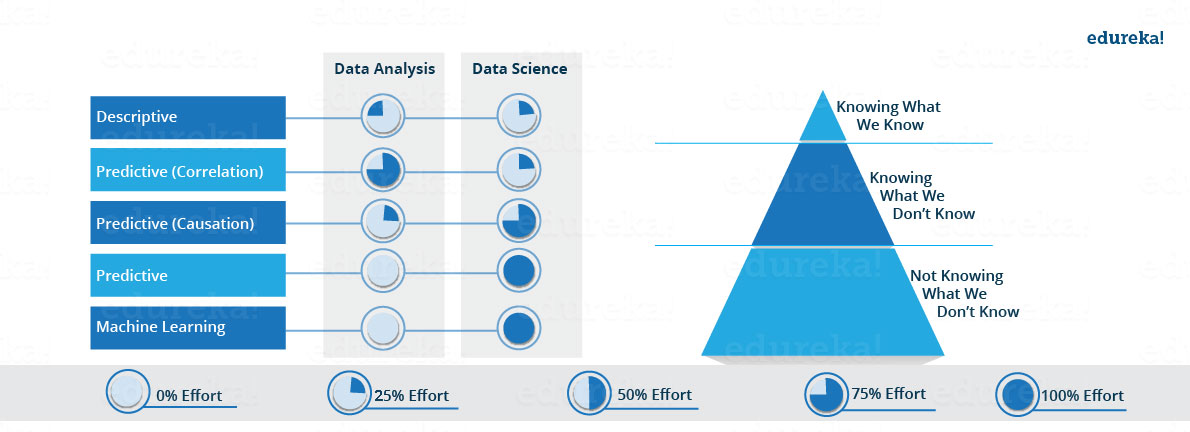
Let’s see how the proportion of above-described approaches differ for Data Analysis as well as Data Science. As you can see in the image below, Data Analysis includes descriptive analytics and prediction to a certain extent. On the other hand, Data Science is more about Predictive Causal Analytics and Machine Learning.
80% INTERVIEW REJECTIONS HAPPEN IN FIRST 90 SECONDS
Take Data Scientist Mock Interview
Get Interviewed by Industry Experts
Personalized interview feedback
I am sure you might have heard of Business Intelligence (BI) too. Often Data Science is confused with BI. I will state some concise and clear contrasts between the two which will help you in getting a better understanding. Let’s have a look.
Business Intelligence (BI) vs. Data Science
BI basically analyzes the previous data to find hindsight and insight to describe the business trends. BI enables you to take data from external and internal sources, prepare it, run queries on it and create dashboards to answer the questions like quarterly revenue analysis or business problems. BI can evaluate the impact of certain events in the near future.
Data Science is a more forward-looking approach, an exploratory way with the focus on analyzing the past or current data and predicting the future outcomes with the aim of making informed decisions. It answers the open-ended questions as to “what” and “how” events occur.
Let’s have a look at some contrasting features.
Features
Business Intelligence (BI)
Data Science
Data Sources
Structured (Usually SQL, often Data Warehouse)
Both Structured and Unstructured
( logs, cloud data, SQL, NoSQL, text)
Approach
Statistics and Visualization
Statistics, Machine Learning, Graph Analysis, Neuro- linguistic Programming (NLP)
Focus
Past and Present
Present and Future
Tools
Pentaho, Microsoft BI, QlikView, R
RapidMiner, BigML, Weka, R
This was all about what is Data Science, now let’s understand the lifecycle of Data Science.
A common mistake made in Data Science projects is rushing into data collection and analysis, without understanding the requirements or even framing the business problem properly. Therefore, it is very important for you to follow all the phases throughout the lifecycle of Data Science to ensure the smooth functioning of the project.
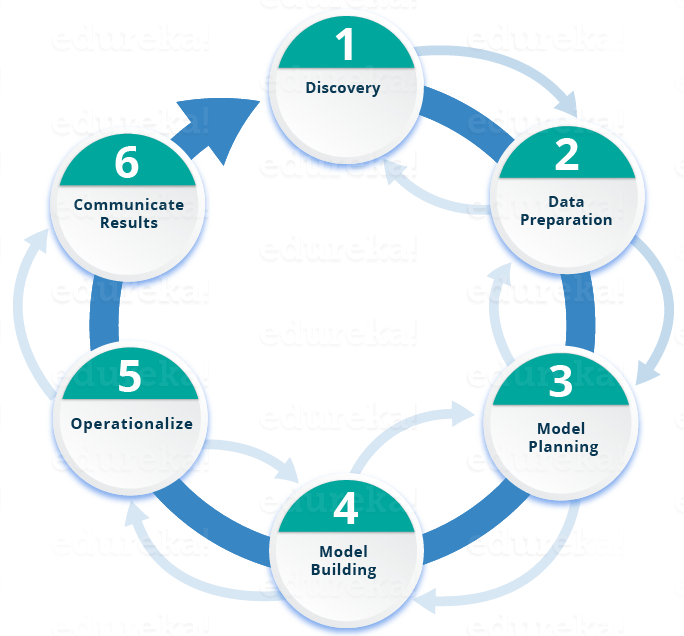
Lifecycle of Data Science
Here is a brief overview of the main phases of the Data Science Lifecycle:
Phase 1—Discovery: Before you begin the project, it is important to understand the various specifications, requirements, priorities and required budget. You must possess the ability to ask the right questions. Here, you assess if you have the required resources present in terms of people, technology, time and data to support the project. In this phase, you also need to frame the business problem and formulate initial hypotheses (IH) to test.
Phase 2—Data preparation:In this phase, you require analytical sandbox in which you can perform analytics for the entire duration of the project. You need to explore, preprocess and condition data prior to modeling. Further, you will perform ETLT (extract, transform, load and transform) to get data into the sandbox. Let’s have a look at the Statistical Analysis flow below.
You can use R for data cleaning, transformation, and visualization. This will help you to spot the outliers and establish a relationship between the variables. Once you have cleaned and prepared the data, it’s time to do exploratory analytics on it. Let’s see how you can achieve that.
Phase 3—Model planning:Here, you will determine the methods and techniques to draw the relationships between variables. These relationships will set the base for the algorithms which you will implement in the next phase. You will apply Exploratory Data Analytics (EDA) using various statistical formulas and visualization tools.
Let’s have a look at various model planning tools.
R has a complete set of modeling capabilities and provides a good environment for building interpretive models.
SQL Analysis services can perform in-database analytics using common data mining functions and basic predictive models.
SAS/ACCESS can be used to access data from Hadoop and is used for creating repeatable and reusable model flow diagrams.
Although, many tools are present in the market but R is the most commonly used tool.
Now that you have got insights into the nature of your data and have decided the algorithms to be used. In the next stage, you will apply the algorithm and build up a model.
Phase 4—Model building: In this phase, you will develop data sets for training and testing purposes. You will consider whether your existing tools will suffice for running the models or it will need a more robust environment (like fast and parallel processing). You will analyze various learning techniques like classification, association and clustering to build the model.
You can achieve model building through the following tools.
Phase 5— Operationalise:In this phase, you deliver final reports, briefings, code and technical documents. In addition, sometimes a pilot project is also implemented in a real-time production environment. This will provide you a clear picture of the performance and other related constraints on a small scale before full deployment.
Phase 6— Communicate results: Now it is important to evaluate if you have been able to achieve your goal that you had planned in the first phase. So, in the last phase, you identify all the key findings, communicate to the stakeholders and determine if the results of the project are a success or a failure based on the criteria developed in Phase 1.
Now, I will take a case study to explain you the various phases described above.
Case Study: Diabetes Prevention
What if we could predict the occurrence of diabetes and take appropriate measures beforehand to prevent it? In this use case, we will predict the occurrence of diabetes making use of the entire life-cycle that we discussed earlier. Let’s go through the various steps.
Step 1:
First, we will collect the data based on the medical history of the patient as discussed in Phase 1. You can refer to the sample data below.
As you can see, we have the various attributes as mentioned below.
Attributes:
npreg – Number of times pregnant
glucose – Plasma glucose concentration
bp – Blood pressure
skin – Triceps skinfold thickness
bmi – Body mass index
ped – Diabetes pedigree function
age – Age
income – Income
Step 2:
Now, once we have the data, we need to clean and prepare the data for data analysis.
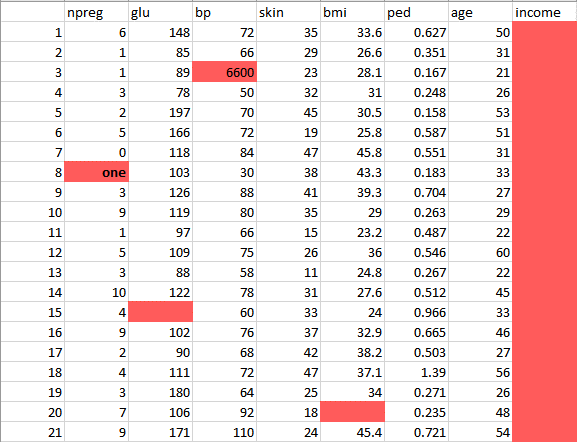
This data has a lot of inconsistencies like missing values, blank columns, abrupt values and incorrect data format which need to be cleaned.
Here, we have organized the data into a single table under different attributes – making it look more structured.
Let’s have a look at the sample data below.
This data has a lot of inconsistencies.
In the column npreg, “one” is written in words, whereas it should be in the numeric form like 1.
In column bp one of the values is 6600 which is impossible (at least for humans) as bp cannot go up to such huge value.
As you can see the Income column is blank and also makes no sense in predicting diabetes. Therefore, it is redundant to have it here and should be removed from the table.
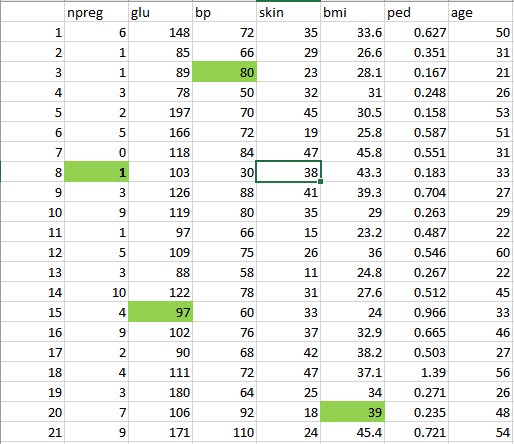
So, we will clean and preprocess this data by removing the outliers, filling up the null values and normalizing the data type. If you remember, this is our second phase which is data preprocessing.
Finally, we get the clean data as shown below which can be used for analysis.
Step 3: Now let’s do some analysis as discussed earlier in Phase 3.
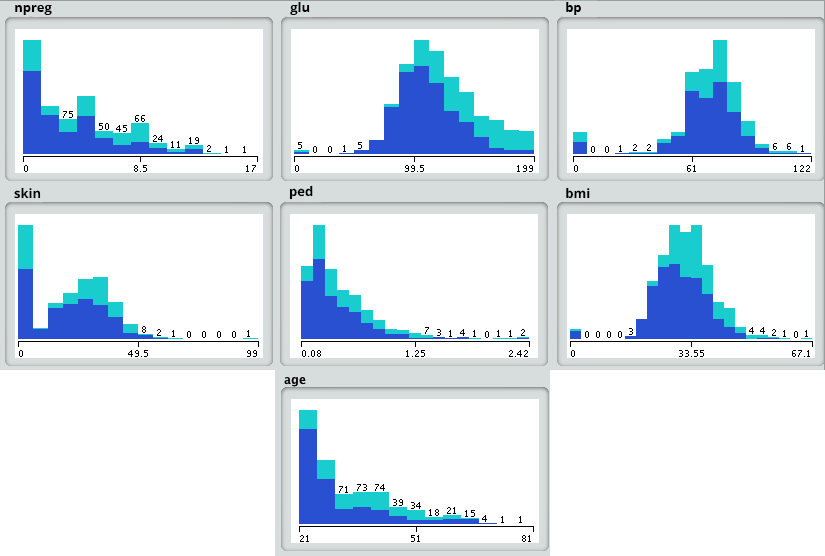
First, we will load the data into the analytical sandbox and apply various statistical functions on it. For example, R has functions like describe which gives us the number of missing values and unique values. We can also use the summary function which will give us statistical information like mean, median, range, min and max values.
Then, we use visualization techniques like histograms, line graphs, box plots to get a fair idea of the distribution of data.
Step 4:
Now, based on insights derived from the previous step, the best fit for this kind of problem is the decision tree. Let’s see how?
Since, we already have the major attributes for analysis like npreg, bmi, etc., so we will use supervised learning technique to build a model here.
Further, we have particularly used decision tree because it takes all attributes into consideration in one go, like the ones which have a linear relationship as well as those which have a non-linear relationship. In our case, we have a linear relationship between npreg and age, whereas the nonlinear relationship between npreg and ped.
Decision tree models are also very robust as we can use the different combination of attributes to make various trees and then finally implement the one with the maximum efficiency.
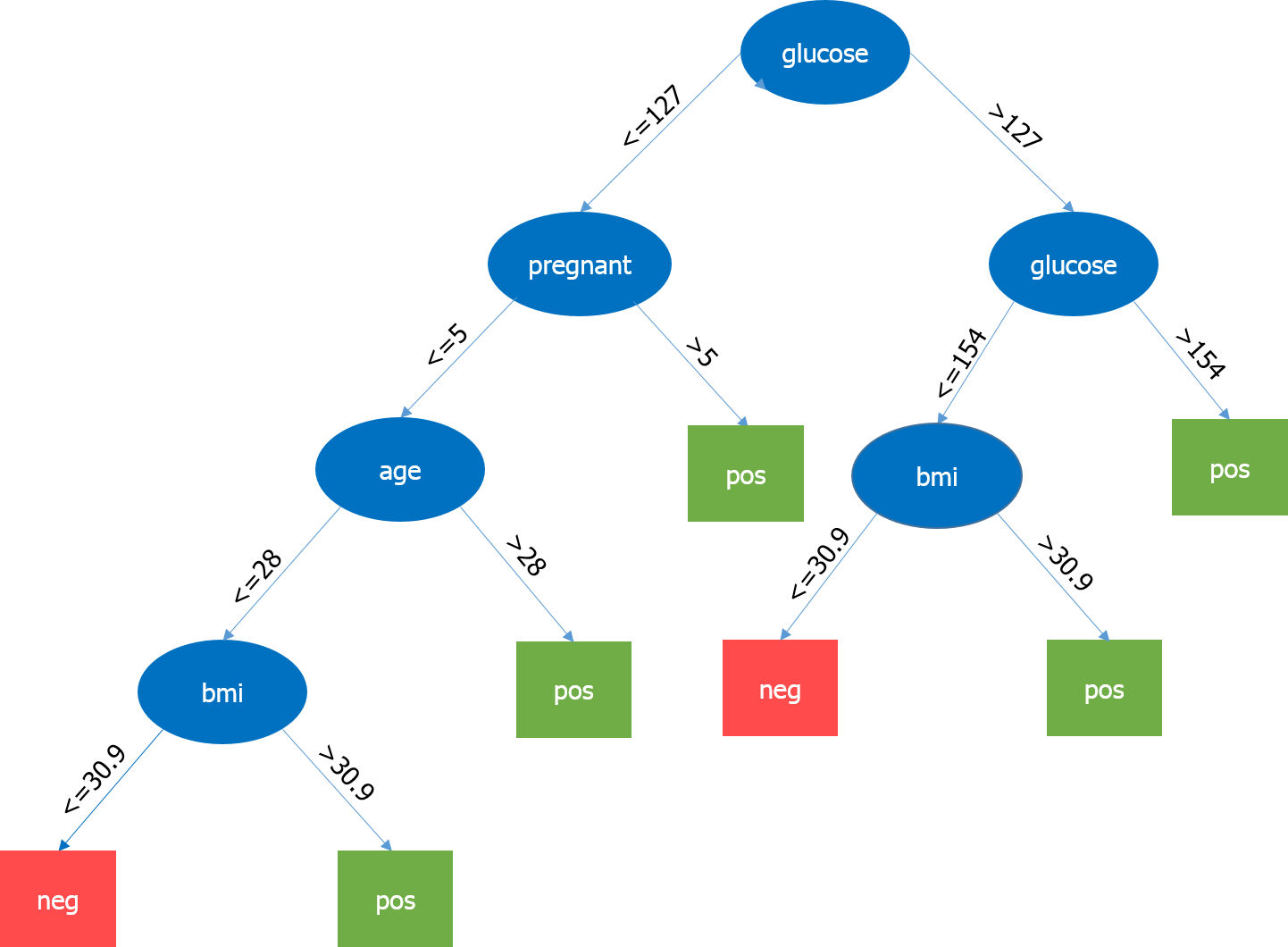
Let’s have a look at our decision tree.
NEED HELP FOR YOUR UPCOMING INTERVIEW?
Take Data Scientist Mock Interview
Get Interviewed by Industry Experts
Personalized interview feedback
Here, the most important parameter is the level of glucose, so it is our root node. Now, the current node and its value determine the next important parameter to be taken. It goes on until we get the result in terms of pos or neg. Pos means the tendency of having diabetes is positive and neg means the tendency of having diabetes is negative.
In this phase, we will run a small pilot project to check if our results are appropriate. We will also look for performance constraints if any. If the results are not accurate, then we need to replan and rebuild the model.
Step 6:
Once we have executed the project successfully, we will share the output for full deployment.
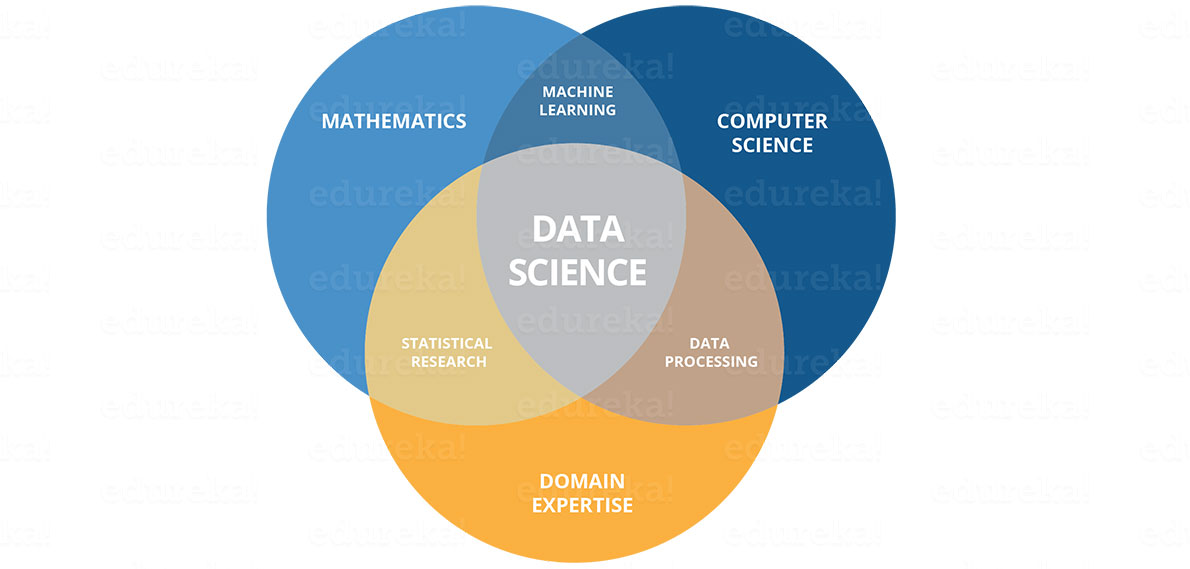
Being a Data Scientist is easier said than done. So, let’s see what all you need to be a Data Scientist. A Data Scientist requires skills basically from three major areas as shown below.
As you can see in the above image, you need to acquire various hard skills and soft skills. You need to be good at statistics and mathematics to analyze and visualize data. Needless to say, Machine Learning forms the heart of Data Science and requires you to be good at it. Also, you need to have a solid understanding of the domain you are working in to understand the business problems clearly. Your task does not end here. You should be capable of implementing various algorithms which require good coding skills. Finally, once you have made certain key decisions, it is important for you to deliver them to the stakeholders. So, good communication will definitely add brownie points to your skills.
I urge you to see this Data Science video tutorial that explains what is Data Science and all that we have discussed in the blog. Go ahead, enjoy the video and tell me what you think.
What Is Data Science? Data Science Course – Data Science Tutorial For Beginners | Edureka This Edureka Data Science course video will take you through the need of data science, what is data science, data science use cases for business, BI vs data science, data analytics tools, data science lifecycle along with a demo.
In the end, it won’t be wrong to say that the future belongs to the Data Scientists. It is predicted that by the end of the year 2018, there will be a need of around one million Data Scientists. More and more data will provide opportunities to drive key business decisions. It is soon going to change the way we look at the world deluged with data around us. Therefore, a Data Scientist should be highly skilled and motivated to solve the most complex problems.
Estio Training Ltd is a specialist Digital Industry Apprenticeship Provider. At Estio we have an Innovation and Development team that focus on digital and online learning.
For more information on Estio Training and our apprenticeships please visit https://estio.co.uk.


 much of the divide between corporations and their stakeholders. Political vacuums are foisting CEOs and brands into leadership roles all around the world. Our report offers corporate leaders a detailed peek ahead, with specific stake holder engagement strategies to meet the risks + opportunities of corporate stewardship head-on through 2020 and beyond.
much of the divide between corporations and their stakeholders. Political vacuums are foisting CEOs and brands into leadership roles all around the world. Our report offers corporate leaders a detailed peek ahead, with specific stake holder engagement strategies to meet the risks + opportunities of corporate stewardship head-on through 2020 and beyond. enterprises have given rise to a debate about the roles and responsibilities of such actors with regard to human rights, and have led to the placement of business and human rights on the UN agenda. Neither legal compliance nor standard risk management tools are sufficient for companies who wish to survive and thrive in the new era. Rather, resilient companies will focus on core values, leadership and a more inclusive approach to business. Check out The UN Guiding Principles and how it applies to you and your buisness.
enterprises have given rise to a debate about the roles and responsibilities of such actors with regard to human rights, and have led to the placement of business and human rights on the UN agenda. Neither legal compliance nor standard risk management tools are sufficient for companies who wish to survive and thrive in the new era. Rather, resilient companies will focus on core values, leadership and a more inclusive approach to business. Check out The UN Guiding Principles and how it applies to you and your buisness.





 Phase 1—Discovery: Before you begin the project, it is important to understand the various specifications, requirements, priorities and required budget. You must possess the ability to ask the right questions. Here, you assess if you have the required resources present in terms of people, technology, time and data to support the project. In this phase, you also need to frame the business problem and formulate initial hypotheses (IH) to test.
Phase 1—Discovery: Before you begin the project, it is important to understand the various specifications, requirements, priorities and required budget. You must possess the ability to ask the right questions. Here, you assess if you have the required resources present in terms of people, technology, time and data to support the project. In this phase, you also need to frame the business problem and formulate initial hypotheses (IH) to test.

 Here, you will determine the methods and techniques to draw the relationships between variables. These relationships will set the base for the algorithms which you will implement in the next phase. You will apply Exploratory Data Analytics (EDA) using various statistical formulas and visualization tools.
Here, you will determine the methods and techniques to draw the relationships between variables. These relationships will set the base for the algorithms which you will implement in the next phase. You will apply Exploratory Data Analytics (EDA) using various statistical formulas and visualization tools.

 In this phase, you deliver final reports, briefings, code and technical documents. In addition, sometimes a pilot project is also implemented in a real-time production environment. This will provide you a clear picture of the performance and other related constraints on a small scale before full deployment.
In this phase, you deliver final reports, briefings, code and technical documents. In addition, sometimes a pilot project is also implemented in a real-time production environment. This will provide you a clear picture of the performance and other related constraints on a small scale before full deployment. Phase 6— Communicate results: Now it is important to evaluate if you have been able to achieve your goal that you had planned in the first phase. So, in the last phase, you identify all the key findings, communicate to the stakeholders and determine if the results of the project are a success or a failure based on the criteria developed in Phase 1.
Phase 6— Communicate results: Now it is important to evaluate if you have been able to achieve your goal that you had planned in the first phase. So, in the last phase, you identify all the key findings, communicate to the stakeholders and determine if the results of the project are a success or a failure based on the criteria developed in Phase 1.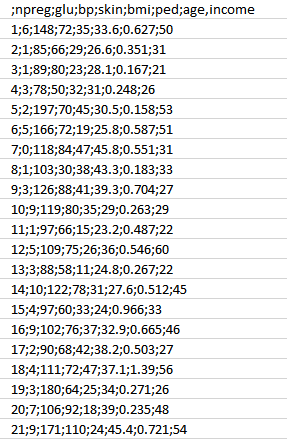

Recent Comments